
Since joining GitHub over 5 years ago I have been working with CodeQL, a Static Application Security Testing (SAST) tool which can identify vulnerabilities and patterns in code. I’ve always been fascinated in developing a language from scratch and going from an empty repository to finding security vulnerabilities in an unsupported language.
This blog series is my knowledge and experience on how to build an extractor, writing your first QL for the different layers needed to perform dataflow, and finally writing a query to find a security vulnerability. Hopefully by the end of the series and each post you will have a better understanding of how you can add support for a language.
These series of posts are from September 2025 and might be a little outdated in the future but generally should be still relevant.
What is an Extractor?
Let’s start off by asking the first question of: “What is an extractor?”
A CodeQL Extractor is a piece of software written in theory in any language that takes the code and transforms it into data which is inserted into a CodeQL database. These can be in the form of hooking into and monitoring the languages compiler at build time such as languages like C#, Java, C/C++ or by parsing file-by-file similar to interpreted languages like Python, JavaScript, etc.
Each language supported by CodeQL has an extractor which is used to do this, most of them are Open Source but some are preparatory. There are a few different components to an Extractor including the configuration file, various scripts, and the extractor itself. Let’s take a look at each of these parts and start building up our extractor.
Building our Extractor
For this blog series we will be looking at building an Extractor for the Lua programming language. Why Lua? It’s a currently unsupported language and it’s an interpreted language so it’s relatively easier than other languages we could look at.
The extractor in this series will be using Tree-Sitter, a parser generator used in various IDEs and GitHub uses it for Code Navigation. For our Lua extractor we will be using a pre-defined grammar provided by the community which is very close to what we want.
For us to build our extractor, we will need 4 core components which need to be implemented:
- the extractor config
- the Rust based extractor
- the Tree-Sitter grammar/parser
- And; the required scripts
Let’s start with the configuration and go through these one by one.
Extractor Configuration File
All extractors use a standard confirmation file called codeql-extractor.yml in the root of the project.
This tells CodeQL a few critical bits of information crucial to use the extractor.
I won’t go over all of the fields but just the important ones for us.
The first fields we are interested in are the name, display name, and version for the extractor. These are the names used when creating databases or defining a language.
name: "lua"
display_name: "Lua"
version: 0.1.0
The next part is the build modes, CodeQL supports different ways of scanning code “autobuild”, “manual”, and “none” (also called build-mode none).
These tell CodeQL which of these are supported by your extractor.
Take a look at the C# Extractor and Python Extractor where you can see the C# extractor supports autobuild and manual where the Python Extractor only supports build-mode none. The reason for this is because Python is an interpreted language while C# is a compiled language which CodeQL hooks into the compiler.
For Lua we want to use build-mode none for our extractor so we can add that to the config.
build_modes:
- none
The last step is to define the language mappings and file types supported by the extractor. These simply tell CodeQL which languages this extractor supports and map those to GitHub’s language API.
The file type list defines the files this extractor supports.
You can add as many file extensions you want to support, in our case we only for now want to support the .lua extension.
github_api_languages:
- Lua
scc_languages:
- Lua
file_types:
- name: lua
display_name: Lua
extensions:
- .lua
If we bring these together with a couple encoding and legacy settings we have an extractor config for Lua.
There are other optional fields like options which are custom arguments to the extractor such as Rust’s extractor allowing an advanced user to select the exact features to enable during analysis.
The configuration is the easy bit so let’s jump into the hard part. The extractor itself.
The Rust based Extractor
We will be writing the extractor in Rust, there are a few reasons for this but the main one is that the shared CodeQL library is written in Rust. This library makes our lives extremely easy to build an extractor.
Let’s start by creating a Cargo workspace project at the root of the project.
All we need in this is the resolve version and the project members which will be just extractor.
[workspace]
resolver = "3" # edition 2024
members = ["extractor"]
Next we need to create an extractor folder in the root of our project, this will be where all of our extractor code will be stored.
This will be the main cargo project where we define the extractor components with a few external dependencies included.
There are two important dependencies we will talk about; the shared CodeQL library and the Tree-Sitter bindings for Lua.
The CodeQL shared Rust Library
The Rust shared library from the CodeQL team is critical for us; it will allow us to generate Tree-Sitter QL abstracts, generate the database scheme from the TS grammar, automatically parse & index the files into our Database, and much more.
You can include the shared library as a Cargo dependencies for the extractor and pin it to a specific version using commit SHA’s like such:
# CodeQL - v2.20.4
codeql-extractor = { git = "https://github.com/github/codeql", rev = "c524a98eb91c769cb2994b8373181c2ebd27c20f" }
Note: We are pinning it to an older version of CodeQL for now as newer versions include features we currently do not want to use as of right now.
Using a Tree-Sitter Grammar for CodeQL
Every language supported by Tree-Sitter has a language grammar which defines the syntax rules of the language. Defining a language grammar is out of the scope for this write-up but we will cover some core elements that will be important to us (if you want to see a deep-dive into this, please let me know on socials).
First lets look for a well defined grammar we can use to parse Lua. There can be a lot of different grammars of different quality and use patterns we do and don’t want. I will be using the tree-sitter-grammars/tree-sitter-lua repository on GitHub for this.
Next we have a few choices of how we can use this grammar in our extractor, each have pros and cons:
- Fork the repository (recommended)
- Either using cargo git dependency (recommended) or submodules
- Pros: Can pull in new updates easily,
- Cons: Two repositories versus one
- Store Tree-Sitter repository in our extractor
- Pros: All the code in one place, easy to reference
- Cons: Not as easy to pull in changes / updates to the grammar
- Use the public crate
- Pros: Super easy to use
- Cons: You can’t edit / change the grammar or tree-sitter
We will be using the recommended way which is forking and using cargo git dependency to reference it. The reason for this is because we have to make a small change to the grammar to make it work correctly with the CodeQL generator and extractor.
We can add the Tree-Sitter repository to our extractor by adding the following lines in our extractors Cargo.toml.
tree-sitter-lua = { git = "https://github.com/geekmasher/tree-sitter-lua", branch = "main" }
Note: I have defined the branch as main, this is for development but once the code is all working you should switch from using branches to using rev and pin a commit SHA.
Before we edit the grammar or change anything, let’s now build out the rest of the CLI.
Create our Extractors CLI
The next phase is to add support for the Rust Extractor with some code to do the following tasks:
- Generator: Generate the Database Scheme and TreeSitter QL library
- Autobuild: Selects the files of the language ready for extractor
- run’s
codeql database index-files ...under the hood
- run’s
- Extrator: Parses files and generates the corresponding TRAP files
For each of these we will create a separate module and update our main.rs to parse the CLI arguments and call each of them as needed. I won’t be adding the full source code of the modules, see the Open Source repository for the full code.
CLI: Generator
For the generator, all we need to do is update the languages variable with all of the languages we want to support in this extractor.
You can use as many languages inside a database you want / need.
Also note that this module has two options that can be passed into the CLI; dbscheme and library which will be used later.
For Lua, all we need to do is add the name (in uppercase, see why in a minute) and reference the Lua NODE_TYPES.
let languages = vec![language {
name: "LUA".to_owned(),
node_types: tree_sitter_lua::NODE_TYPES,
}];
Depending on the version of the CodeQL shared library, you might need to update this a little but generally it should work.
CLI: Autobuild
Now for the autobuild module, all we need to do is update the environment variables and update the Autobuilder builder pattern to have the information we need to index the files. In our case, we need to update the “work in process database” variable to the following:
let database = env::var("CODEQL_EXTRACTOR_LUA_WIP_DATABASE")
.expect("CODEQL_EXTRACTOR_LUA_WIP_DATABASE not set");
And then update the Autobuilder to use the correct Lua variables:
autobuilder::Autobuilder::new("lua", PathBuf::from(database))
.include_extensions(&[".lua"])
.exclude_globs(&["**/.git"])
.size_limit("10m")
.run()
You can add all of the files that you want to index, set the file size limit (10 Mb is a good number), and exclude globs to stop indexing of specific files like .git directory. Finally, let’s update the extractor module.
CLI: Extractor
For the extractor module we will have to define a few different parts to get this to work. We will be using the “simple extractor” provided by the CodeQL team as this covers most of the use cases we have. The main change comes when defining the Extractor itself where we have to update the different fields with our Lua specifics.
First, we need to update the prefix to our language (in our case lua). This is mainly just used for the CodeQL logger for the extractor.
prefix: "lua".to_string(),
The next section where we define all of the different languages we want to parse using a Vector of LanguageSpec, this is where we have to fill in the four fields for our language. The ts_language and node_types are from the Tree-Sitter Lua Rust bindings. Depending on the version of the generated Tree-Sitter parser, you might need to edit / update this (see section XXX for more information on this).
languages: vec![
// lua
LanguageSpec {
prefix: "lua",
ts_language: tree_sitter_lua::LANGUAGE.into(),
node_types: tree_sitter_lua::NODE_TYPES,
file_globs: vec!["*.lua".into()],
},
],
// ...
Finally we need to define the TRAP directory, TRAP compression, source archive dir, and the list of files to be extracted. Both the TRAP directory and source archive come from the CLI arguments passed in my CodeQL so we let CodeQL manage that for us. The TRAP compression is set via an environment variable called CODEQL_${LANGUAGE}_TRAP_COMPRESSION which is also handled by CodeQL. The file list is the absolute path of the file we want to extractor, the path passed into the extractor might need to be normalised so we use the file_paths::path_from_string() function to do that.
let file_list = file_paths::path_from_string(&options.file_list);
let file_lists: Vec<PathBuf> = vec![file_list];
let extractor = Extractor {
// ...
trap_dir: options.output_dir,
trap_compression: trap::Compression::from_env("CODEQL_LUA_TRAP_COMPRESSION"),
source_archive_dir: options.source_archive_dir,
file_lists,
};
CLI: Main
The last part is to bring this all together in the main.rs which we can simply add the three modules we defined moments ago, define a CLI enum for clap to use as subcommand to our CLI, and define a main function.
All the main function needs to do now is parse the arguments being passed into the CLI and based on what subcommand it called run the appropriate submodule command along with there options.
Building and Finalising the Extractor
Now that we have all of the Rust code defined (yes, that is all the rust we need) we can build the project. In the root of the project now you can run cargo build which will build the extractor.

Success! So is that it? Are we done? Not quite.
The next phase is to build a CodeQL Extractor Pack, this is just the name used for a final CodeQL extractor that is compiled and bundled into a directory. There are specific requirements that need to be met for this extractor to work as CodeQL expects a few files to be inside of an extractor pack. The files are:
- autobuild.sh / autobuild.cmd: For running autobuild
- index-files.sh / index-files.cmd: For indexing the files
- pre-finalize.sh / pre-finalize.cmd: Script to run before finalizing the database (used for indexing other secondary languages like JSON/YAML)
- qltest.sh / qltest.cmd: Similar to
index-filesbut specifically for indexing tests
These tools are the glue between the CodeQL CLI and the extractors being called which all extractors have. There are both Unix (Linux & Macos) and Windows scripts which are automatically run by CodeQL based on the operating system you are using.
The main reason for using these scripts is to allow the extractor author to select the correct extractor binary to use. An example is if you compile the extractor for X86 Linux using GLibC on a M4 Apple MacOS it will just fail to run. There are also pre-defined environment variables passed into the script by CodeQL such as the extractor root directory CODEQL_EXTRACTOR_${LANGUAGE}_ROOT and the platform being run on CODEQL_PLATFORM which can help direct the script to use the right extractor.
We can define define the autobuild.sh for example using the following line:
exec "${CODEQL_EXTRACTOR_LUA_ROOT}/tools/${CODEQL_PLATFORM}/extractor" autobuild
All this does is run the extractor in the root of the extractor pack using the correct platform and passing in the correct arguments (in this case autobuild). The different platforms are stored in their own folders, think linux64, osx64, and win64.
All of these tools are defined and stored in the tools folder in the root of the project. This just helps us distinguish between the extractor scripts (tools) and other scripts we will be defining next.
Bringing it all Together with the Creating Extractor Pack script
Now we have the tools, let’s create a script to bring it all together which we’ll store in a scripts directory. Create a script called create-extractor-pack.sh and let’s see what we need to do to create the extractor pack.
The first step is to define both the language and the platform we are building for (this script can be run on Linux or MacOS) so we can store the extractor in the correct location.
This can be done using the $OSTYPE variable which is set by the shell and we can set the platform to the correct value which we’ll be using later.
LANGUAGE="lua"
if [[ "$OSTYPE" == "linux-gnu"* ]]; then
platform="linux64"
elif [[ "$OSTYPE" == "darwin"* ]]; then
platform="osx64"
else
echo "Unknown OS"
exit 1
fi
The next step is to detect if CodeQL is installed on the machine we are compiling on. This is mainly to format the TreeSitter.qll that is generated by the generator step so this isn’t totally necessary but I think this really nice to have as the generate QLL file isn’t super readable.
if which codeql >/dev/null; then
CODEQL_BINARY="codeql"
elif gh codeql >/dev/null; then
CODEQL_BINARY="gh codeql"
else
gh extension install github/gh-codeql
CODEQL_BINARY="gh codeql"
fi
Next we need to compile a release version of our extractor using cargo (or cross).
cargo build --release
Next we want to run the extractor generator subcommand as this will generate the TreeSitter.qll and the database scheme files we need to use the database. We are also making sure that the correct directories are created for the CodeQL Pack.
mkdir -p "ql/lib/codeql/${LANGUAGE}/ast/internal/"
cargo run --release --bin "codeql-extractor-${LANGUAGE}" -- \
generate \
--dbscheme "ql/lib/${LANGUAGE}.dbscheme" \
--library "ql/lib/codeql/${LANGUAGE}/ast/internal/TreeSitter.qll"
You can see that the --dbscheme and --library were defined in the generator earlier. These need to be stored in the root of the QL Pack (ql/lib) for the database scheme and in the AST internal folder for the TreeSitter.qll. We won’t be talking about these until the next post in this series.
You can run the script now and it will now compile and run the extractors generator.
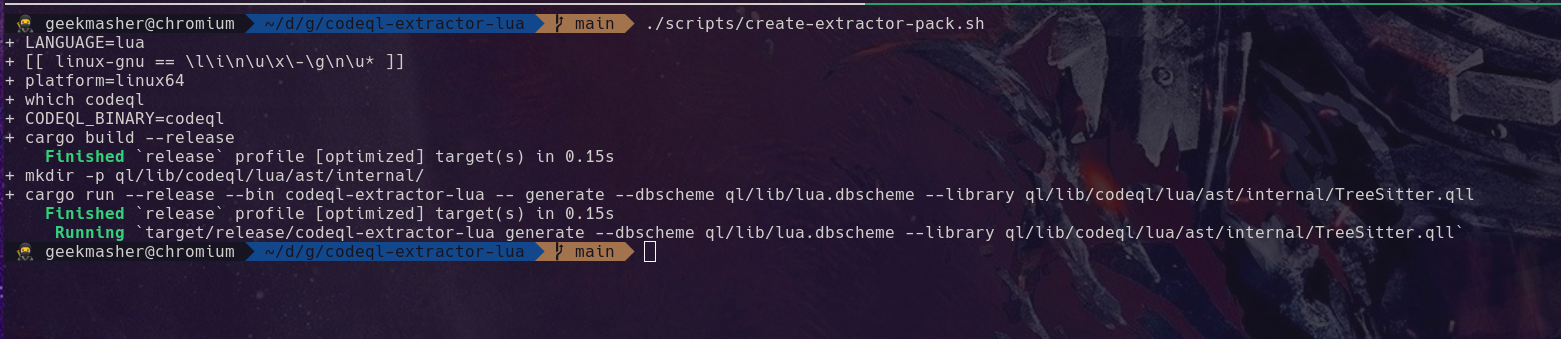
Before we continue with writing the script, we need to add an important file that isn’t generated for us which is the dbscheme.stats file. This is a small XML file that is needed by CodeQL but we can just create the simplest version of the file to make sure CodeQL works. This should be placed in ql/lib/lua.dbscheme.stats along with the database schema.
<dbstats>
<typesizes></typesizes>
<stats></stats>
</dbstats>
Now back to the script, next we will be creating the extractor pack folder in the root of the project called extractor-pack and copy all of the following:
- CodeQL Extractor Config (codeql-extractor.yml)
- Tools directory
- Database scheme and stats file
- Compiled extractor
This can be done in a few lines:
mkdir -p extractor-pack
cp -r codeql-extractor.yml tools "ql/lib/${LANGUAGE}.dbscheme" "ql/lib/${LANGUAGE}.dbscheme.stats" extractor-pack/
# Tools
mkdir -p extractor-pack/tools/${platform}
cp "target/release/codeql-extractor-${LANGUAGE}" "extractor-pack/tools/${platform}/extractor"
chmod +x extractor-pack/tools/*.sh
You should see the extractor pack folder created with all of the files copied into it.
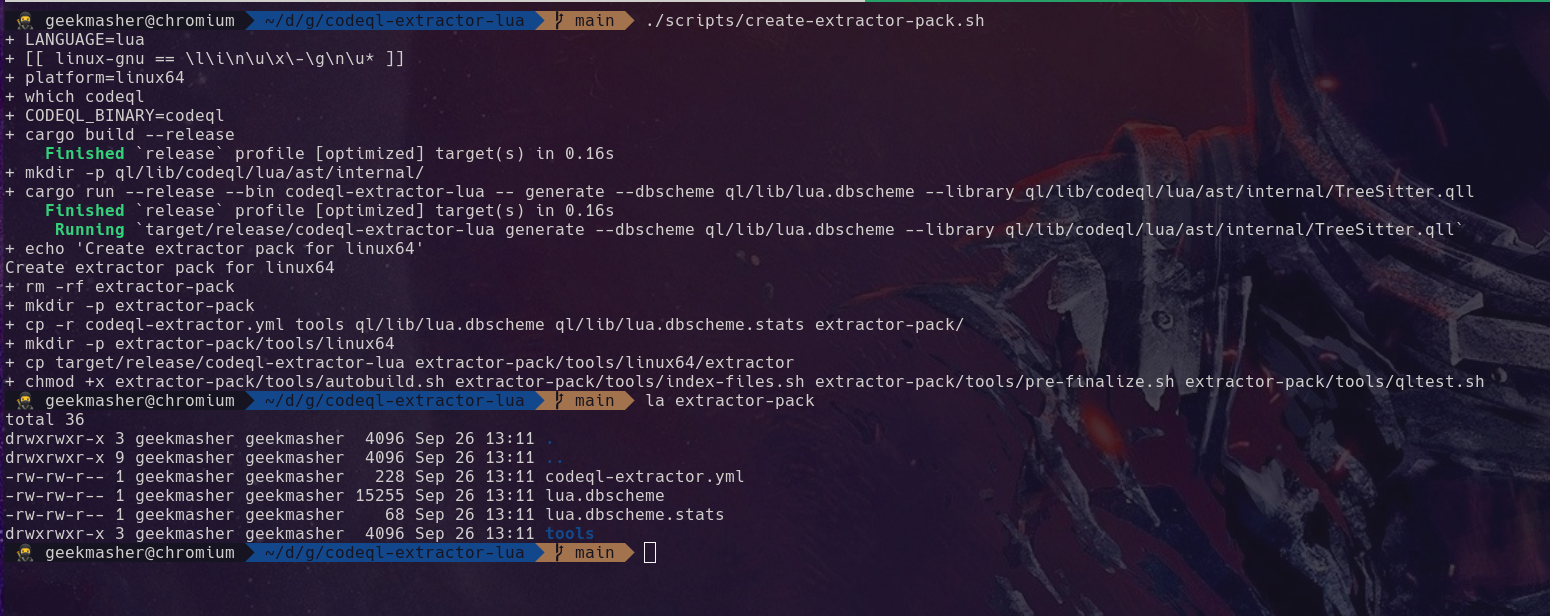
Along with the tools copied in and a folder with the platform you are building on (in my case, Linux).
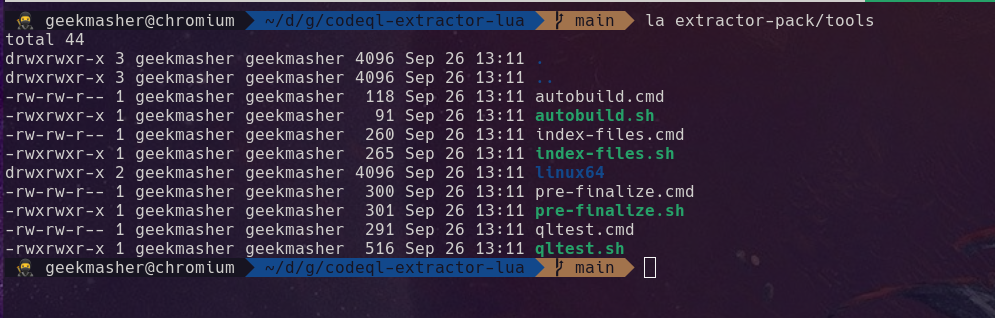
You also want to make sure that the correct execution flags are set for the tools.
To make sure that CodeQL correctly identifies the extractor, you can run the resolve languages command setting the search-path to the extractor-pack folder.
codeql resolve languages --format json --search-path $PWD/extractor-pack
Amazing, now we have an extractor pack ready to use.
Testing the Extractor
Now we have an extractor, how do we test it and make sure that the database is indexing the correct files? The easiest way to do this is to write some code in the language you are adding support for and run a codeql database command.
First, create a directory called testing in the root of the project and create the files you want to index for the tests. In my case, its a 50 lines of Copilot generated lua (see here) in a file called app.lua.
Next we need to run a codeql database create command with a few options set. The main options to take note of is the language set being lua and the search path is the location of the extractor-pack.
codeql database create \
--language=lua \
--search-path=./extractor-pack \
--source-root="./testing" \
./.codeql/
This command will create a Lua database for us and store it in .codeql folder.
You can open up the database in VSCode and see if the database loads correctly or (and the simplest) is to check for the baseline-info.json and see how many lines of code (comments are excluded from the count) and the files that were indexed. You can see below the extractor has indexed 29 lines of Lua code.

Tips, Tricks, and Debugging
This section (continuously evolving over time) is for pointing out tips and tricks you can use to improve the extractors or learn about pitfalls that can occur along with some debugging suggestions.
Tip: Forking and Cloning
I recommend forking the original TreeSitter grammar repository so you can make changes but I recommend you also clone (not submodule) the repository into the extractor directory (exclude from git). This means you can update the grammar locally, re-generate the parser, and when you rebuild the extractor you can quickly test your changes.
tree-sitter-lua = { path = "./tree-sitter-lua" }
Tip: Reviewing and Updating Tree-Sitter Grammars
Now, if you have followed my steps up until this point for Lua (forking the Lua Tree-Sitter) you might have seen an issue once you try to generate the Database Scheme… It doesn’t correctly generate the database scheme or the TreeSitter.qll. This is because of various edge cases with the CodeQL Generator with specific grammars. I have tried this with several languages and most were found but some cause this issue (always in regards to symbols being used).
In the future hopefully the CodeQL generator will catch these edge cases but for the time being, you can always update the Tree-Sitter grammar to make it more usable by CodeQL. Here is the simple change I made to the Lua grammar which fixed the issue.
Tip: Making sure your parser and extractor is up to update
Make sure that if you update the grammar / parser you both re-generate the parser using tree-sitter-cli and re-build the extractor-pack. You might have strange issues where you have updated it and its not working correctly. This can lead to a lot of frustration (I have been here).
Update the the parser using tree-sitter-cli:
tree-sitter-cli generate
Update the extractor:
./scripts/create-extractor-pack.sh
Debugging: Tree-Sitter Language Version Discrepancies
When using TreeSitter parsers, the code generated in the (typically) ./src folder might use an older or newer version than CodeQL shared library is expecting. This is only found at runtime when using the extractor. Example of this below:

Note: This is a mock example manually setting the parser.c language version to 16.
The easiest way to check is by looking at the following:
- The version of CodeQL shared library (little hard to do)
- Checking the version is in the generated code
src/parser.c- Example:
#define LANGUAGE_VERSION 15
- Example:
- Checking the
Cargo.toml(in the tree-sitter repo) and the generated binding code atbindings/rust/Cargo.toml
To resolve this, you can install the version of the tree-sitter-cli which generates the version of the parser you need / want. You should make sure that the parser.c and possibly the binding/rust/lib.rs has been updated. Re-build the extractor and create a database to check if everything is correct and working.
Conclusion
There we have it. We started off with an empty repository and ended up with an extractor for the Lua programming language. This guide should work for any language with a well-defined grammar and can be fully automated if you so wanted to.
All of the code for this series can be found at github.com/geekmasher/codeql-extractor-lua.
The next post will be talking about creating your QL Packs and starting to implement the AST layer for our programming language. Here is the blog series. Stay tuned for that post in the upcoming weeks.